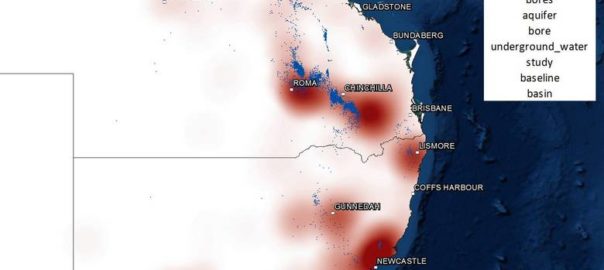
My last post focussed on my progress in making sense of the Where dimension of the public discourse on coal seam gas, including how the Where intersects with the What. This post is about the Who. Somehow, I’ve managed to say almost nothing on this blog so far about the Who dimension of my data. Nearly all of what I’ve written has been about the What, Where and When. It’s time to rebalance this equation.
Until recently, the Who dimension of my data was represented only by a pool of Australian news organisations (at more than 300 sources, it was admittedly a rather large pool), as I was working just with the data I retrieved from the Factiva news database. Now that I have incorporated additional data that I scraped from the websites of community, governments and industry stakeholders (as discussed in my last post), the Who dimension has become a little bit richer. Before I start exploring questions about specific stakeholders and news organisations, or make decisions about which sources I might want to exclude all together, I want to survey the full breadth of sources in my data. I want the birds-eye view. But how to get it?
Who × When ÷ Where = Wha…?
In the previous post, I listed all of my stakeholder sources in colourful tables showing the production of content over time. Initially I thought that doing the same thing with 300 news sources would be ridiculous, but then I figured it might just be ridiculous enough to work. Through a creative deployment of Excel’s conditional formatting feature, I managed to make what you see in Figure 1. Each horizontal band is an individual news source, and the darkness of the band corresponds with the number of articles produced by that source per quarter. Within each state, the sources are grouped by region, although I haven’t indicated where these groupings begin and end (maybe next time!).
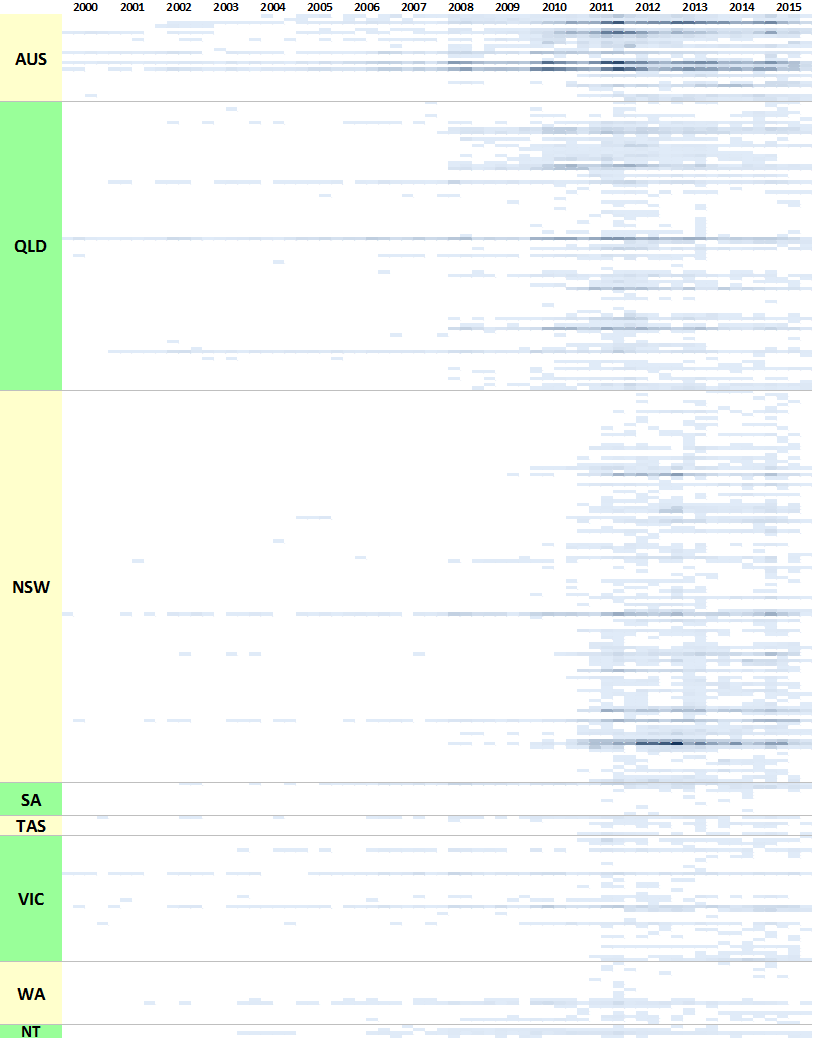
For an experiment that I didn’t take very seriously, this viz actually isn’t too bad. It highlights several features of the data that are useful to know. Firstly, it shows that very few publications have been reporting on coal seam gas continuously since 2000. Nationally, there are The Australian, The Financial Review, Australian Associated Press, and Reuters News (these are not labelled on the graph, so you’ll have to take my word for it). In Queensland, there are the Courier-Mail, the Gold Coast Bulletin, and (to a lesser extent) the Townsville Bulletin. In New South Wales, there has been more-or-less continuous coverage from the Sydney Morning Herald, and somewhat patchier coverage from the Newcastle Herald. The long horizontal lines in Victorian part of the chart represent the Herald Sun and The Age. Continue reading The Who dimension