For so long, climate change has been discussed in Australia (and indeed elsewhere) as if it were an abstract concept, a threat that looms somewhere in the future. Not anymore. In 2019, climate change became a living nightmare from which Australia may never awake.
While I prepared this post in the dying weeks of 2019 and the beginning of 2020, there was not a day when some part of the country was not on fire. As at 24 January, more than 7.7 million hectares — that’s an area about the size of the Czech Republic — have burned. Thirty-three people have died. Towns have been destroyed. Old-growth forests have burned. Around a billion animals have been killed. Whole species have probably been lost.
The effects were not only felt in the bush. Capital cities such as Sydney, Melbourne and Canberra endured scorching temperatures while choking in smoke. Newspaper front pages (except those of the Murdoch press) became a constant variation on the theme of red. The country entered a state of collective trauma, as if at war with an unseen and invincible enemy.
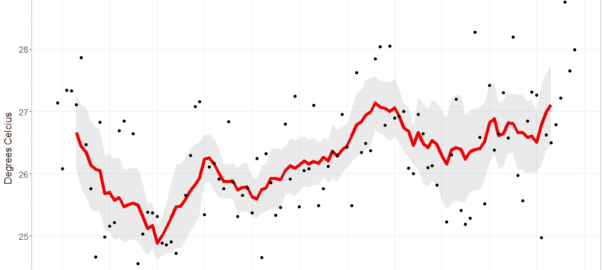
The connection between the bushfires and climate change has been accepted by nearly everyone, with the notable exception of certain denialists who happen to be running the country — and even they are starting to change their tune (albeit to one of ‘adaptation and resilience’). One thing that is undeniable is that 2019 was both the hottest and driest year Australia has experienced since records began, and by no small margin. In December, the record for the country’s hottest day was smashed twice in a single week. And this year was not an aberration. Eight of the ten hottest years on record occurred in the last 10 years. Environmentally, politically, and culturally, the country is in uncharted territory.
Climate deserters
I watched this nightmare unfold from my newly adopted city of Melbourne, to which I moved from Brisbane with my then-fiancée-now-wife in January 2019. As far as I can tell, Melbourne has been one of the better places in the country to have been in the past few months. The summer here has been pleasantly mild so far, save for a few horrific days when northerly winds baked the city and flames lapped at the northern suburbs. It seems that relief from the heat is never far away in Melbourne: the cool change always comes, tonight or tomorrow if not this afternoon. During the final week of 2019, as other parts of Victoria remained an inferno, Melbourne reverted to temperatures in the low 20s. We even got some rain. It was almost embarrassing.
Finding relief from the heat is one of the reasons my wife and I moved to Melbourne. Having lived in Brisbane all of our lives, we were used to its subtropical summers, but the last few pushed us over the edge. To be sure, Brisbane rarely sees extreme heat. In summer, the maximums hover around 30 degrees, and rarely get beyond the mid-30s. But as Brisbanites are fond of saying (especially to southerners ), it’s not the heat, it’s the humidity that gets you. The temperature doesn’t have to be much about 30 degrees in Brisbane before comfort levels become thoroughly unreasonable. Continue reading Confessions of a climate deserter