NOTE: This post discusses the most recent version (v2.0) of the Trove KnewsGetter. You can obtain the latest version from the GitHub page.
Around about this time last year, I hatched a side-project to keep me amused while finishing my PhD thesis (which is still being examined, thanks for asking). Keen to apply my new skills in text analytics to something other than my PhD case study (a corpus of news texts about coal seam gas), I decided to try my hand at analysing historical newspapers. In the process, I finally brought my PhD back into contact with the project that led me to commence a PhD in the first place.
I’m talking here about my other blog, which explores (albeit very rarely, these days) the natural history of the part of Brisbane in which I grew up. Pivotal to the inception of that blog was the publicly available collection of historical newspapers on Trove, a wondrous online resource maintained by the National Library of Australia. Having never studied history before, I became an instant deskchair historian when I discovered how easily I could search 100 years of newspapers for the names of streets, waterways, parks — and yes, even people. I trawled Trove for everything I could find about Western Creek and its surrounds, so that I could tell the story how this waterway and its catchment had been transformed by urbanisation.
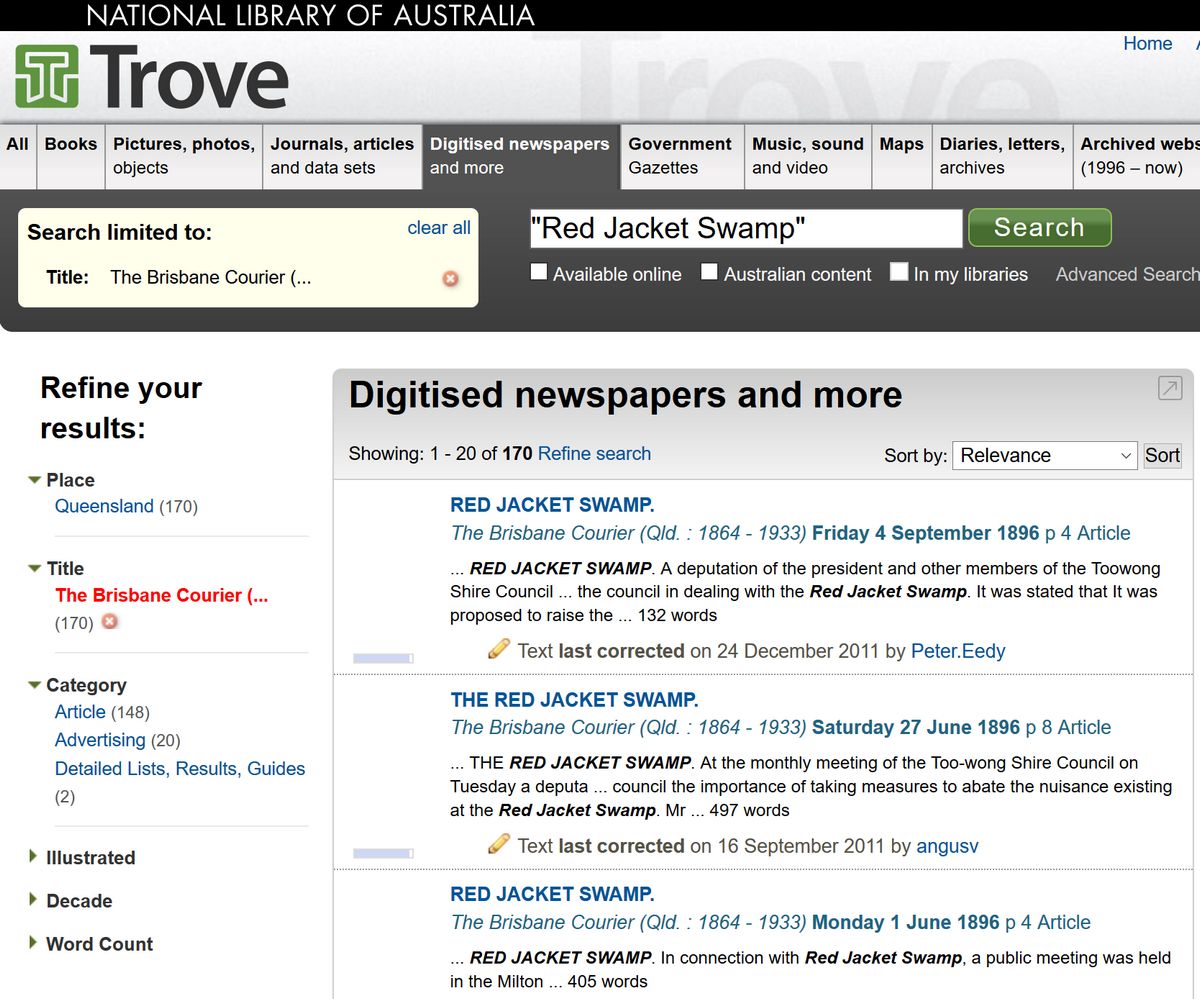
How anyone found the time and patience to study history before there were digitised resources like Trove is beyond me. I cannot even imagine how many person-hours would be needed to replicate the work performed by a single keyword search of Trove’s collection. The act of digitising and indexing textual archives has revolutionised the way in which historical study can be done.
But keyword searches, as powerful as they are, barely scratch the surface of what can be done nowadays with digitised texts. In the age of algorithms, it is possible to not merely index keywords, but to mine textual collections in increasingly sophisticated ways. For example, there are algorithms that can tell the difference between ordinary words and different kinds of named entities, like places or people. Another class of algorithms goes beyond counting individual keywords and instead detect topics — collections of related words that correspond with recurring themes in a collection of texts.
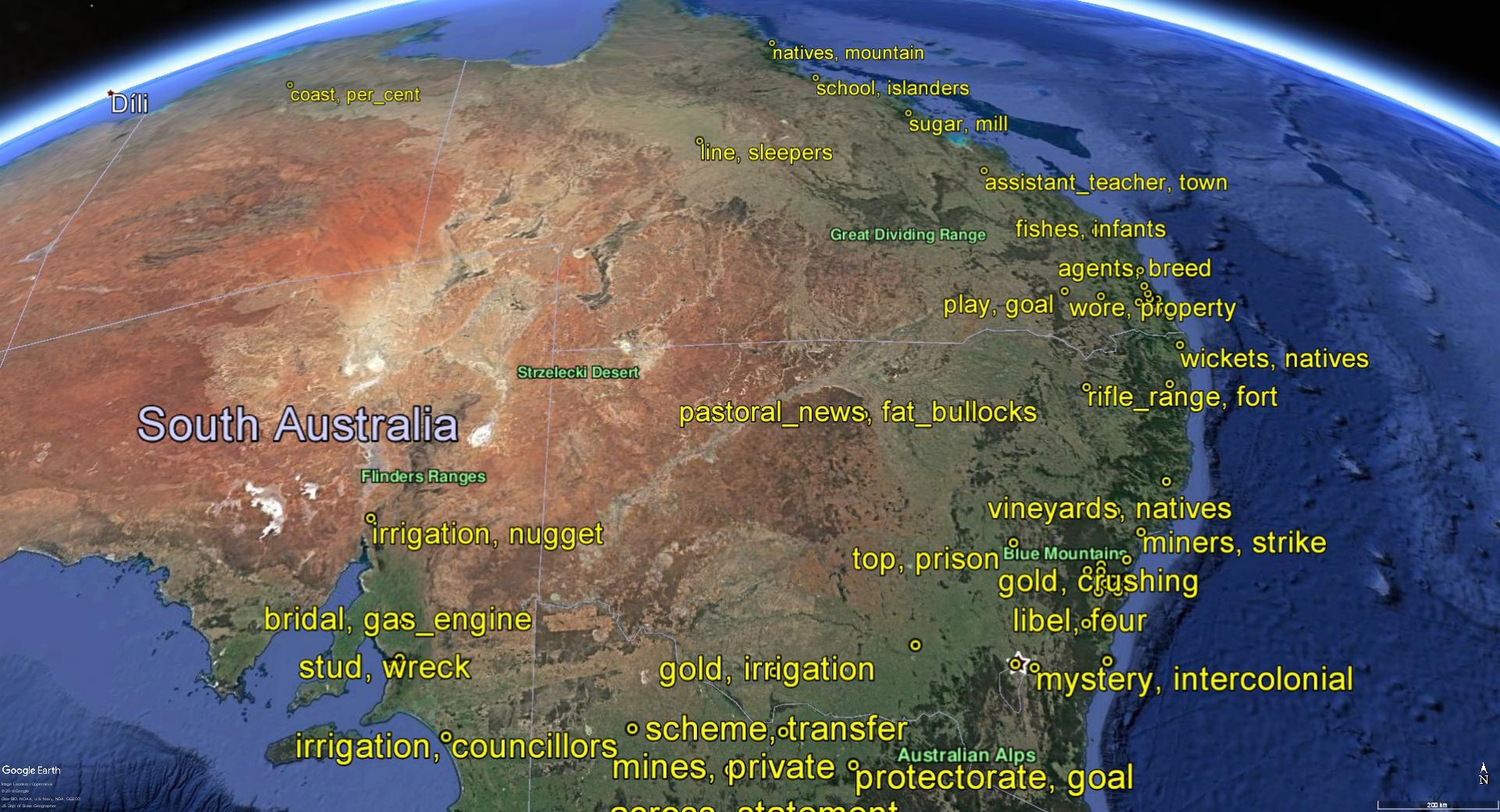
My PhD thesis was largely a meditation on these latter types of algorithms, known as topic models. Along the way, I also used named entity recognition techniques to identify place names and relate them to topics, ultimately enabling me to map the geographic reach of topics in the text.
These were the sorts of techniques that I wanted to bring to apply to Trove’s historical newspapers through my side-project last year. The outcome of this project was a paper that I presented at the Australian Digital Humanities conference in Adelaide in September 2018. To this day, it remains a ‘paper’ in name only, existing only as a slideshow and a lengthy post on my other blog. Releasing some more tangible outputs from this project is on my to-do list for 2019.
In this post, I am going to share the first in what will hopefully be a series of such outputs. This output is a workflow that performs the foundational step in any data analysis — namely, acquiring the data. I hereby introduce the KnewsGrabber — a Knime workflow for harvesting newspaper articles from Trove.
Who ordered that?
I’m far from the first person to download and analyse text in bulk from Trove. This is a path that has already been trodden by others, most notably Tim Sherratt, who has created a Trove Newspaper Harvester in Python, implemented in a user-friendly Jupyter notebook as well as a web interface, to do exactly what I have created the KnewsGetter to do.
So why did I make the KnewsGetter? I suppose the main reason was workflow integration: I do all the rest of my analyses within Knime, so it made sense to keep everything under the one roof. In addition, I was attracted to the challenge of building a Trove harvester in Knime, as I’d never used Knime before to work with an API. As it happens, in the process of revising this workflow, I’ve ventured into what is for me new territory. In many ways, this workflow functions more like an application than a simple sequence of operations. 1 This is the beauty of tools like Knime and Jupyter notebooks: you start off tinkering with simple scripts, and then realise one day that you know how to code (or to Kode, in my case).
Whether anyone else will find a use for this workflow is an open question. If you are already familiar with Tim Sherratt’s harvester, I can’t promise much more with KnewsGetter other than a different interface and a few more point-and-click options. But if you’re curious to explore Knime’s potential for digital humanities research, then perhaps the KnewsGetter will bring you some joy.
Getting the Knews
Once you have installed Knime, downloaded the KnewsGetter workflow from GitHub, and loaded it into Knime, you will see something like this:

Perhaps you’ll find this sight less scary than a page of annotated code, or perhaps not. In any case, there is not much that you need to do to start getting data from Trove.
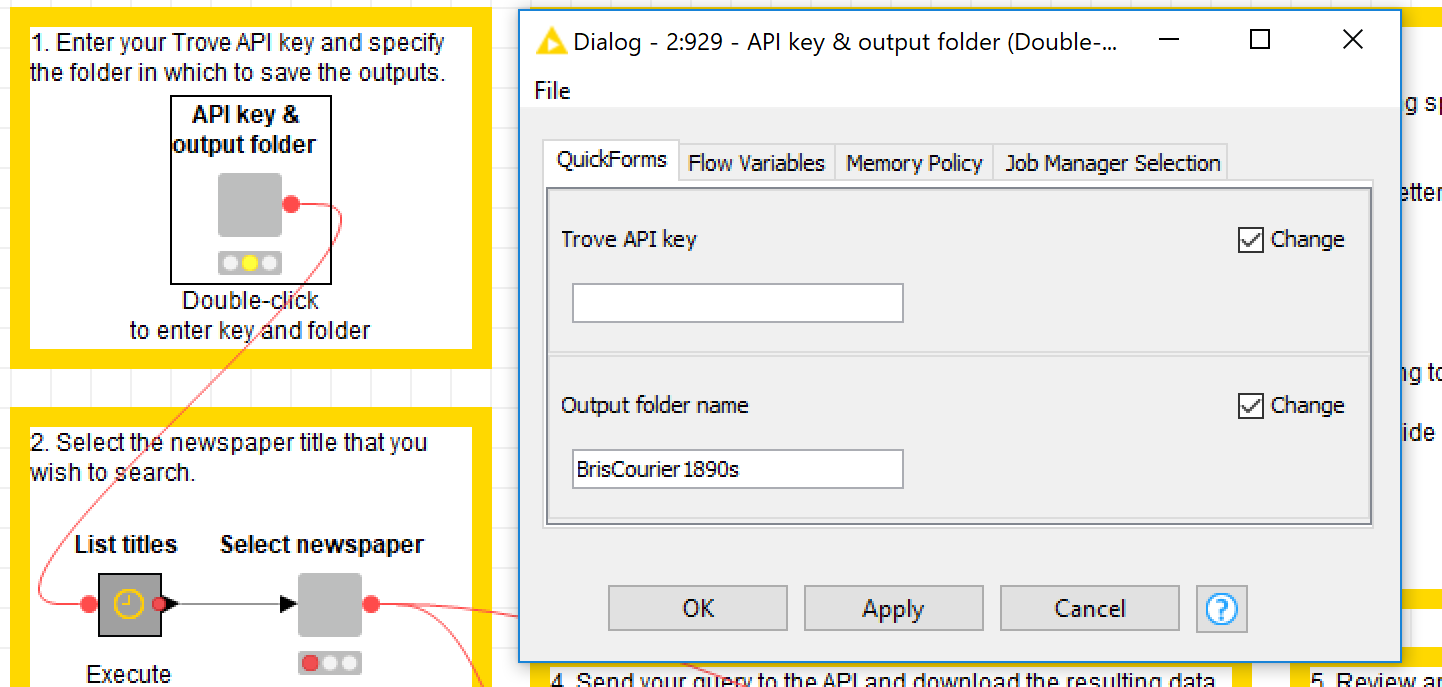
One thing that you will need to do first is obtain a Trove API key. If you don’t already have one, just follow these instructions. Once you have your key, enter it into the workflow by double-clicking the first grey box. This grey box is an example of a wrapped metanode, a really neat feature of Knime that allows data to be entered or selected via quickforms. Just about everything that you’ll need to do in this workflow will be done through quickforms like this one. (In this and all other such forms, ignore the ‘Change’ boxes on the right. They’re just a reminder that you’re working with a workflow editor, not a user-facing application.)
In this form you also specify the name of a folder in which to save your outputs. The workflow will create this folder in a subfolder called ‘Data’ within your Knime workspace. The initial outputs will be in CSV format and could be very large, depending on the scope of your search. The files will be named automatically using information from the query.
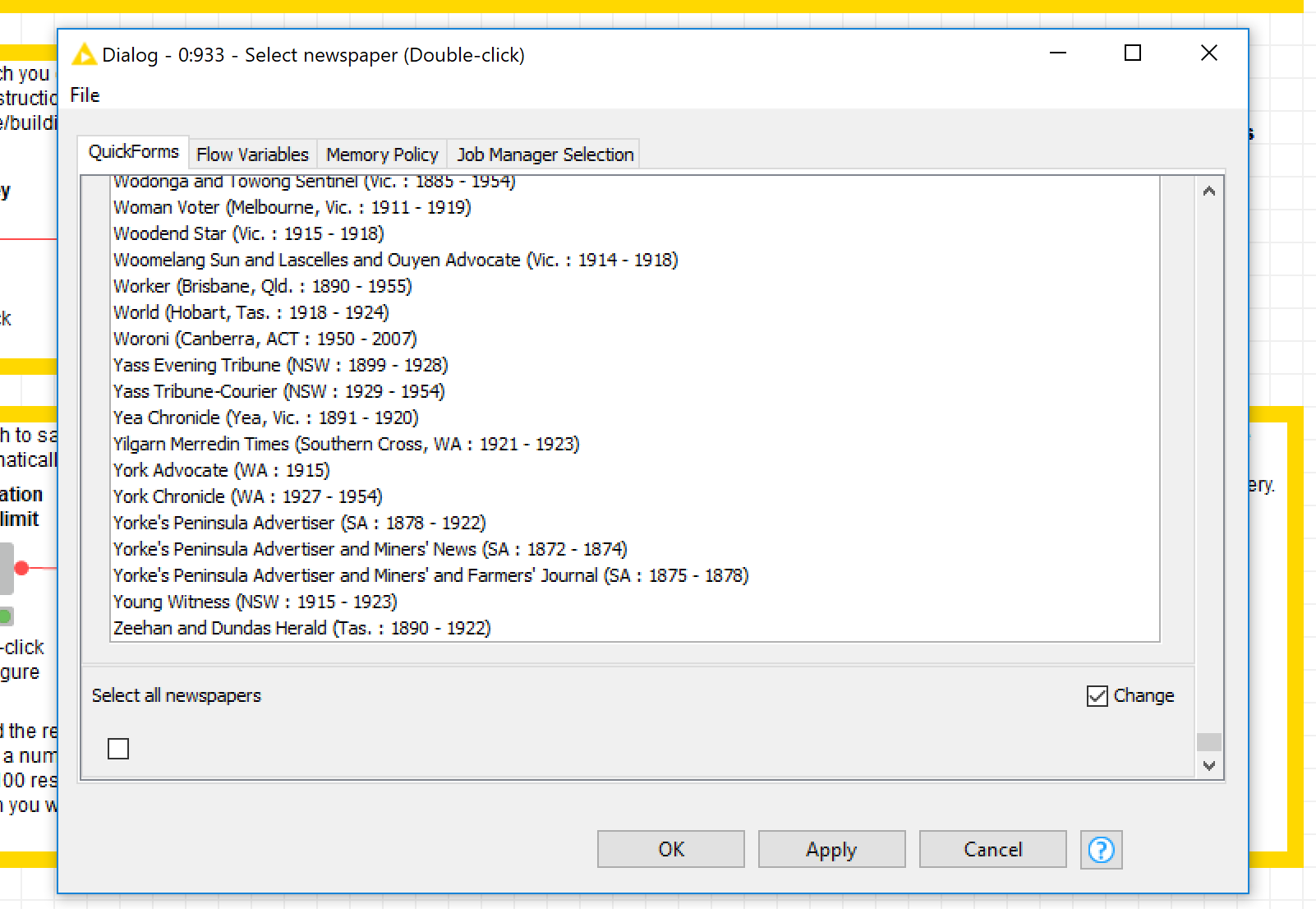
Once you’ve entered your API key, you can choose the newspaper that you are interested in. (The list of titles is itself generated through the API, hence the need to submit your key first.) The next metanode will provide you with a long list of titles to choose from. You can choose one — and only one — or you can search the entire collection by scrolling all the way to the bottom and checking the ‘Select al newspapers’ box. (Yes, this box should be at the top of the list, but sadly, Knime doesn’t let you rearrange the quickforms in wrapped metanodes.)
A third form allows you to enter some specifics of your query. These include a keyword or phrase (leave this blank to retrieve all articles regardless of their content), a decade or year (I’m still working on allowing a defined time range), and one or all of the pre-defined content categories (articles, advertisements, detailed lists, and family notices). You can also choose whether to retrieve the full text of the articles or just the basic metadata. Finally, you can choose to limit the search results to a defined number of pages (there are 100 results per page).
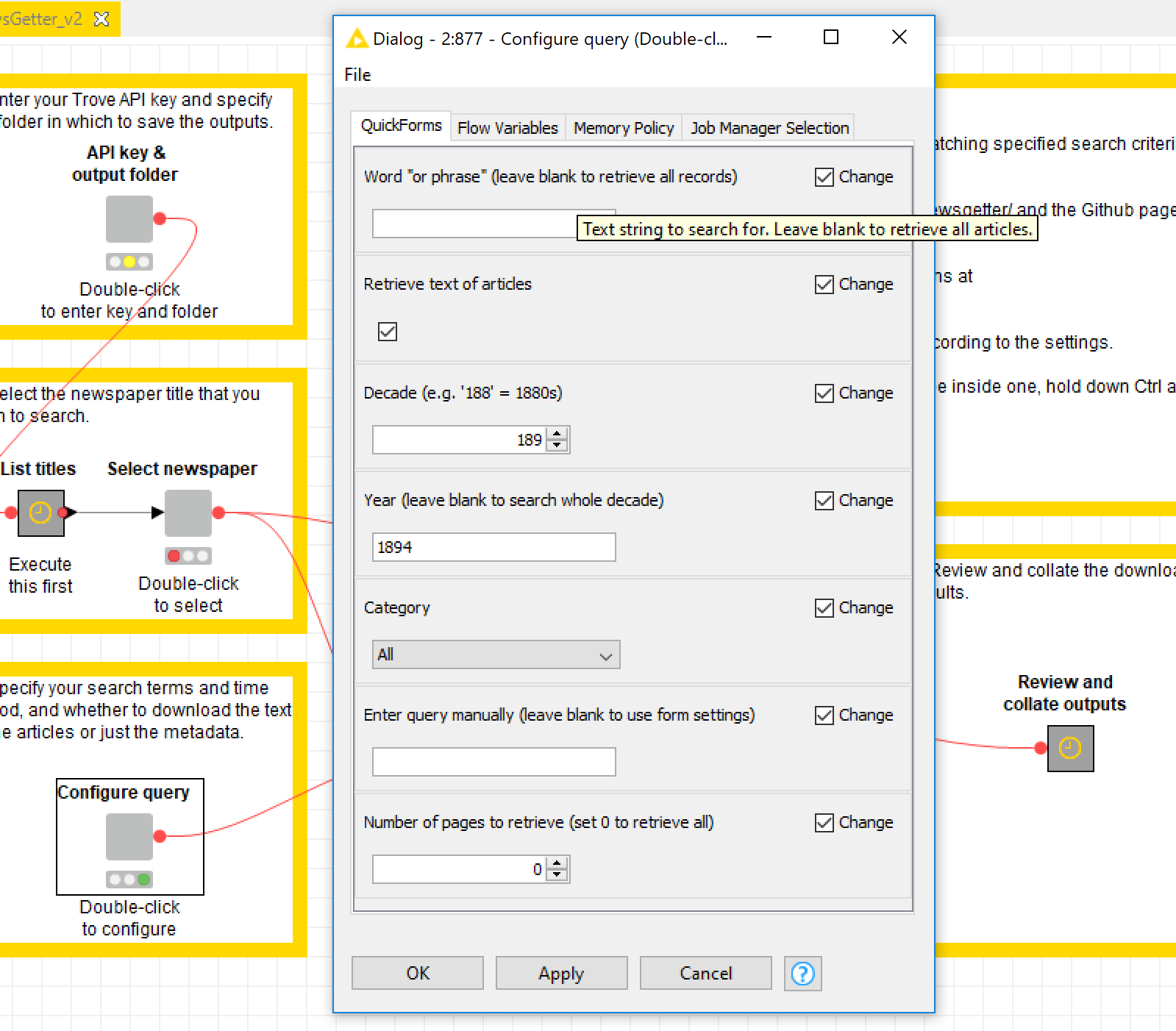
The Trove API allows you to define your search via many more properties than the ones available here. To keep things simple, I’ve stuck to the basic options that I think people are most likely to use. If you know what you are doing and want to use a more specialised query, you can enter it manually into the last part of the configuration form. Doing this will bypass the details entered elsewhere in the form.
You are now ready to run the query by executing the ‘Execute query’ metanode. However, first you might want to check how many results there will be. Do this by executing and viewing the output of the metanode labelled ‘Check number of results’, as shown below.
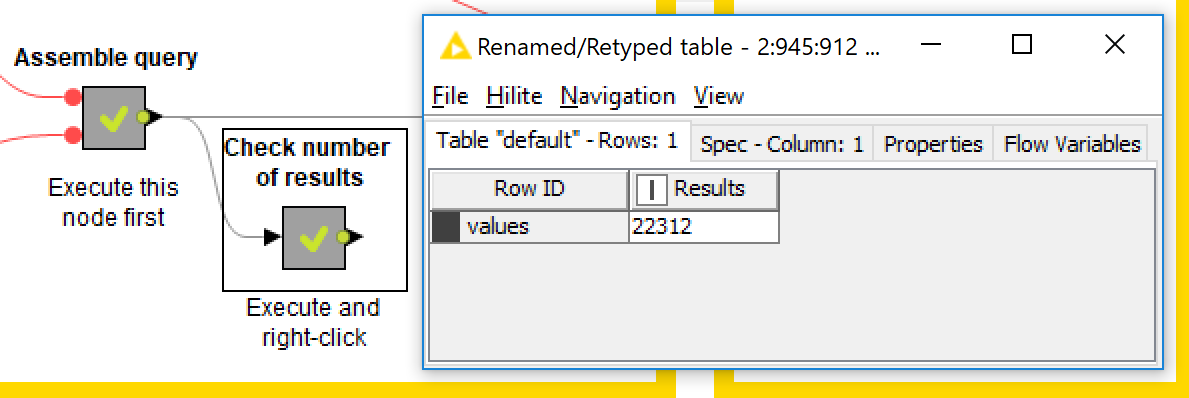
If the number here is really big, just be prepared to wait a while for the download to complete, and make sure there is plenty of space on your hard drive. As mentioned earlier, if you want to digest the query in smaller chunks, you can limit the number of pages to download.
If the process looks like taking longer than you had hoped, you can cancel the download at any time (just hit the ‘Cancel all running nodes’ icon in the top menu) and resume later on. The KnewsGetter works by iteratively building a CSV file, 100 articles at a time. So if you stop the process, you’ll still have everything you have downloaded up to that point. To resume the job, double-click the ‘Execute query’ node and select ‘Continue last query’. The workflow will then bypass all other settings and use the query parameters saved in a file called Next-start.csv, which lives in your selected output folder. If you run a new query, this file will be overwritten, so if you want to resume your first query later on, you will need to save a copy of this file and reinstate it when you are ready.
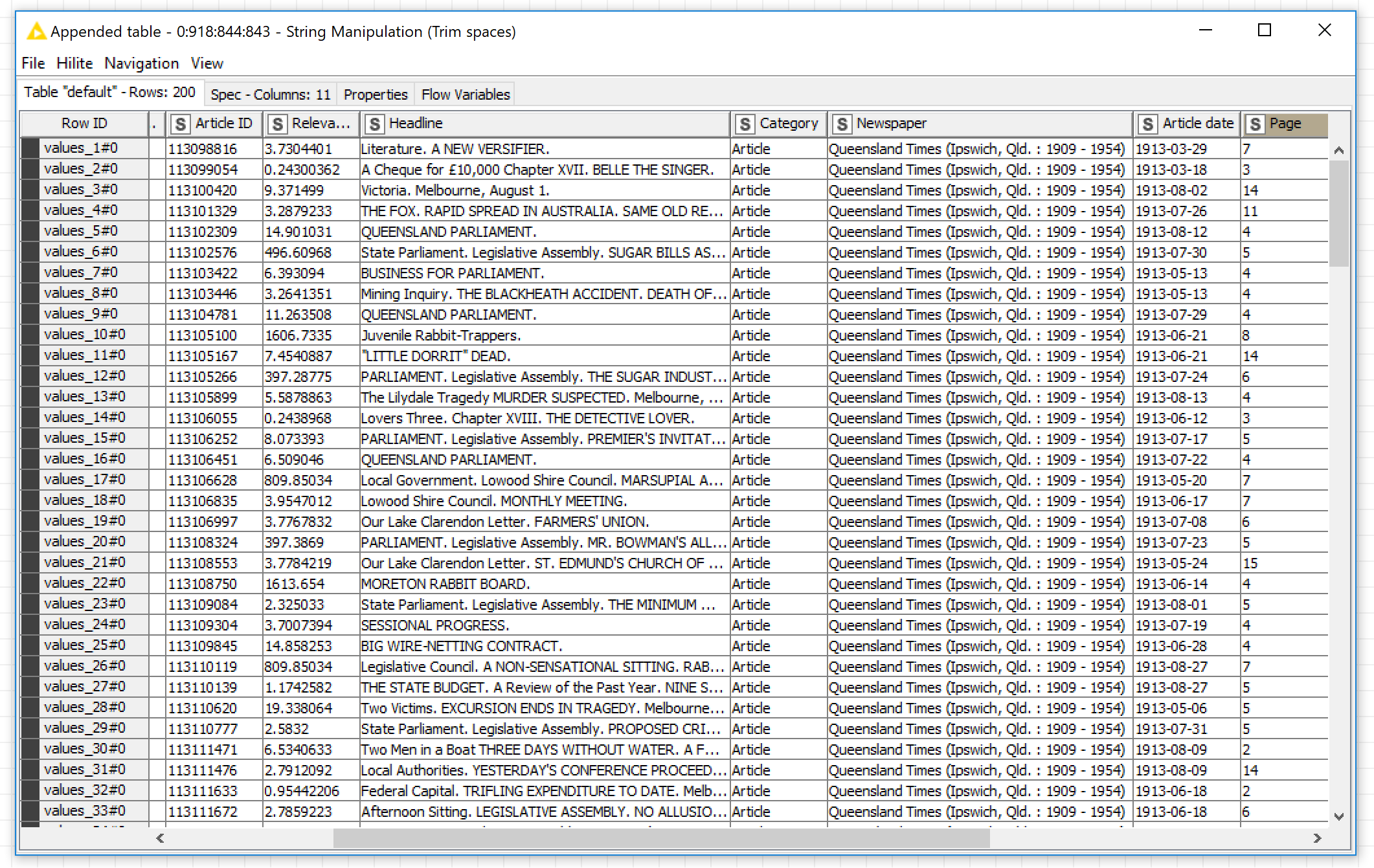
You can view the downloaded outputs in one of two ways. If you have allowed the job to complete, rather than interrupting it part-way through, you can view the output of the ‘Execute query’ metanode, which should look something like the example below. If the table is empty or contains only one row, then something has gone wrong.
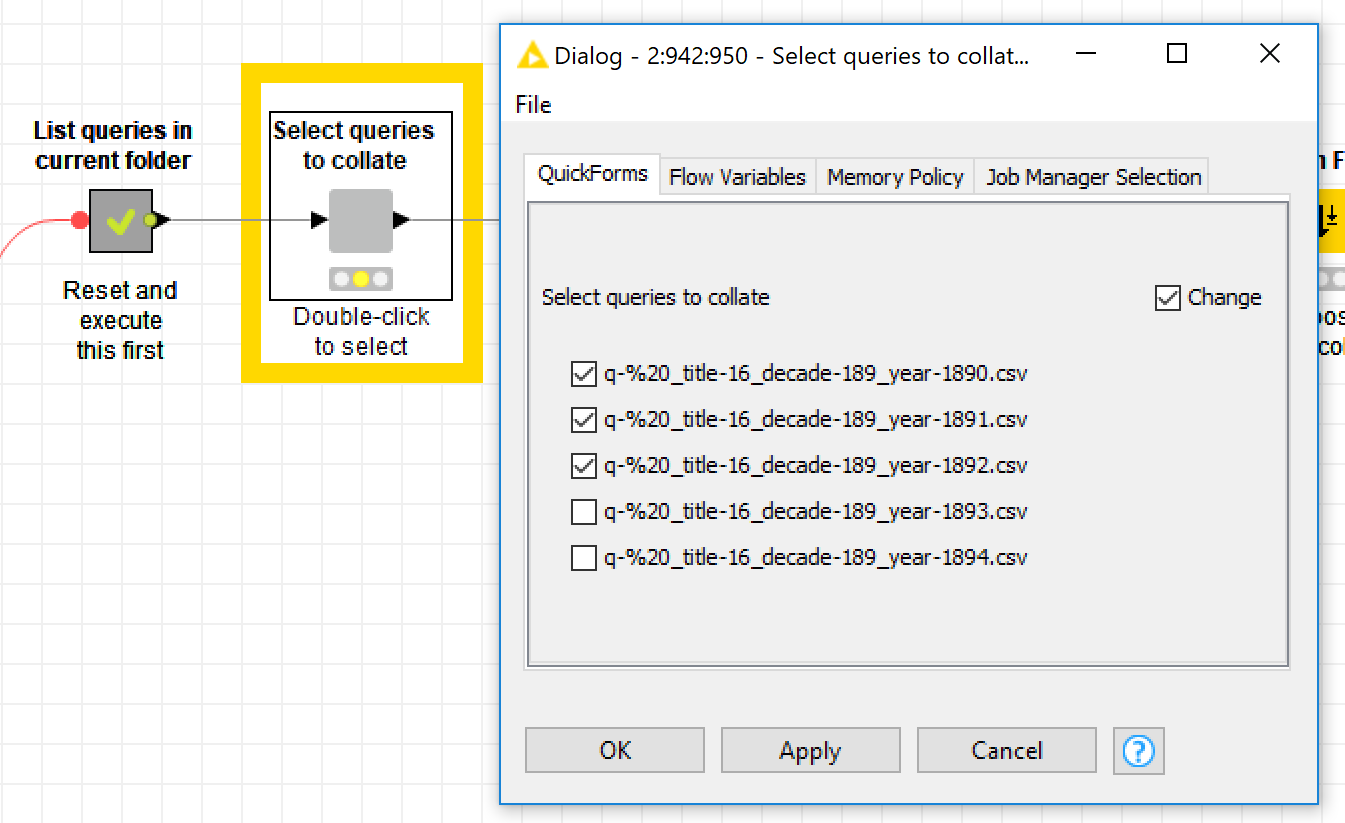
You can also view the downloaded results by poking around in the ‘Review and collate outputs’ metanode. Here, you can select one or more of your CSV files, collate them into a single table, and save the consolidated table as a new CSV file or Knime table. If you will be using Knime to analyse the data, then I recommend choosing the latter option, as it results in a smaller file that is easier to load within Knime.
Congratulations! You now have a dataset. What happens next is up to you. In the near future, I hope to release some more Knime workflows with which you can enrich, explore and and analyse outputs like these.
If you do try out this workflow and run into any problems, please let me know. I can’t promise a rapid response to any bugs, but I certainly do want to iron them out where they exist. For that matter, feel free to get in touch even if it works perfectly. Just knowing that there is someone else out there using Knime to do digital humanities will make my day!
In case you missed it, here is the link to the GitHub page where you can download the workflow.
Notes:
- Indeed, using the functionality of Knime Server, I could probably turn this workflow into a web interface. But sadly, this commercial extension of Knime’s capabilities does not come cheap. ↩