NOTE: This post discusses the most recent version (v2.0) of the Trove KnewsGetter. You can obtain the latest version from the GitHub page.
Around about this time last year, I hatched a side-project to keep me amused while finishing my PhD thesis (which is still being examined, thanks for asking). Keen to apply my new skills in text analytics to something other than my PhD case study (a corpus of news texts about coal seam gas), I decided to try my hand at analysing historical newspapers. In the process, I finally brought my PhD back into contact with the project that led me to commence a PhD in the first place.
I’m talking here about my other blog, which explores (albeit very rarely, these days) the natural history of the part of Brisbane in which I grew up. Pivotal to the inception of that blog was the publicly available collection of historical newspapers on Trove, a wondrous online resource maintained by the National Library of Australia. Having never studied history before, I became an instant deskchair historian when I discovered how easily I could search 100 years of newspapers for the names of streets, waterways, parks — and yes, even people. I trawled Trove for everything I could find about Western Creek and its surrounds, so that I could tell the story how this waterway and its catchment had been transformed by urbanisation.
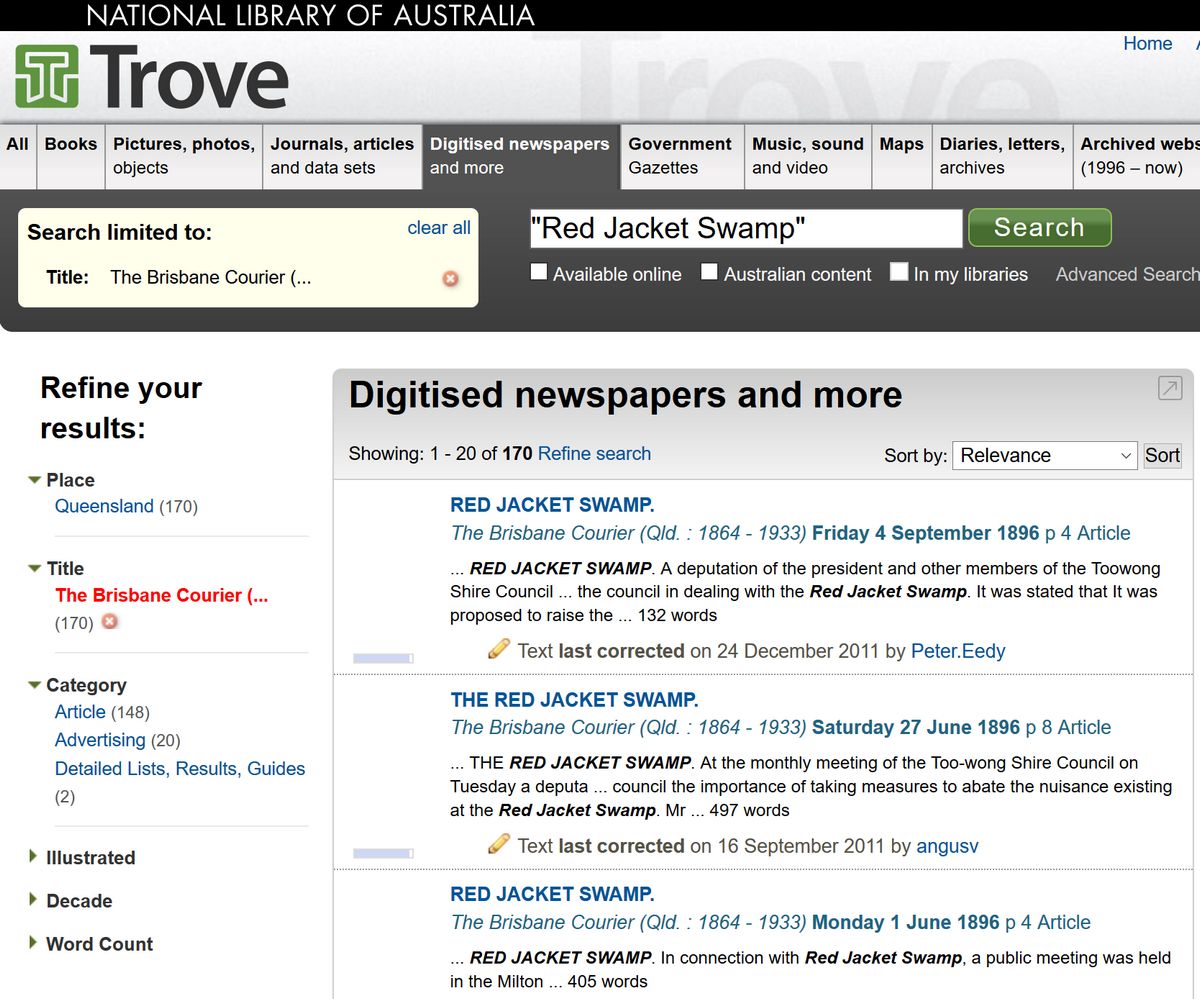
How anyone found the time and patience to study history before there were digitised resources like Trove is beyond me. I cannot even imagine how many person-hours would be needed to replicate the work performed by a single keyword search of Trove’s collection. The act of digitising and indexing textual archives has revolutionised the way in which historical study can be done.
But keyword searches, as powerful as they are, barely scratch the surface of what can be done nowadays with digitised texts. In the age of algorithms, it is possible to not merely index keywords, but to mine textual collections in increasingly sophisticated ways. For example, there are algorithms that can tell the difference between ordinary words and different kinds of named entities, like places or people. Another class of algorithms goes beyond counting individual keywords and instead detect topics — collections of related words that correspond with recurring themes in a collection of texts.
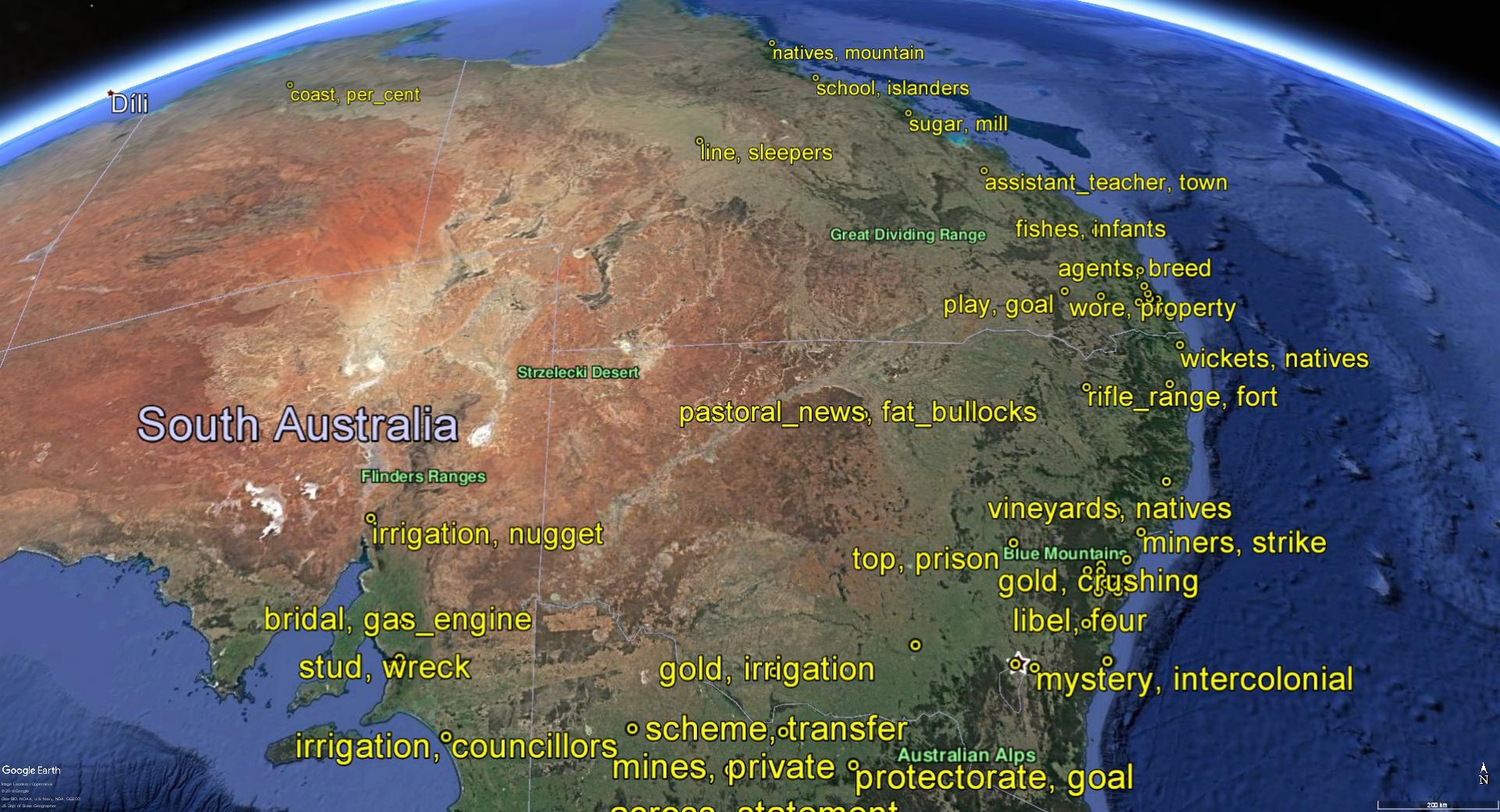
My PhD thesis was largely a meditation on these latter types of algorithms, known as topic models. Along the way, I also used named entity recognition techniques to identify place names and relate them to topics, ultimately enabling me to map the geographic reach of topics in the text.
These were the sorts of techniques that I wanted to bring to apply to Trove’s historical newspapers through my side-project last year. The outcome of this project was a paper that I presented at the Australian Digital Humanities conference in Adelaide in September 2018. To this day, it remains a ‘paper’ in name only, existing only as a slideshow and a lengthy post on my other blog. Releasing some more tangible outputs from this project is on my to-do list for 2019.
In this post, I am going to share the first in what will hopefully be a series of such outputs. This output is a workflow that performs the foundational step in any data analysis — namely, acquiring the data. I hereby introduce the KnewsGrabber — a Knime workflow for harvesting newspaper articles from Trove. Continue reading KnewsGetter: a Knime workflow for downloading newspaper texts from Trove