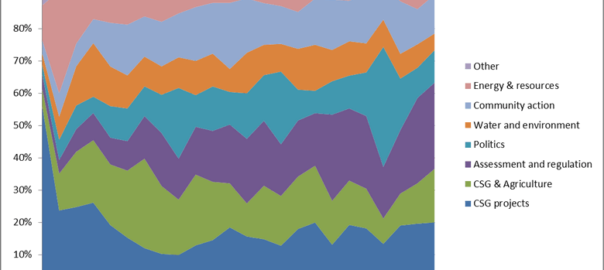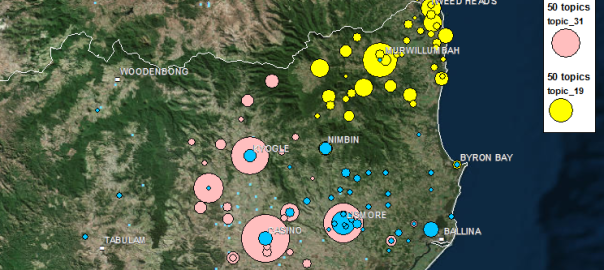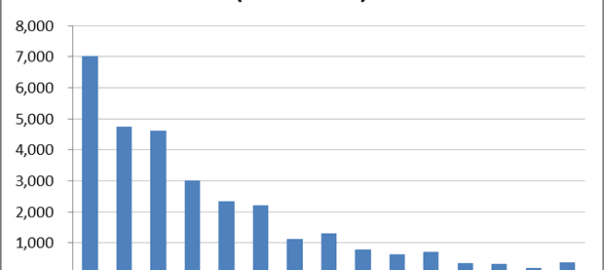
When was the last time you read a newspaper? I mean an actual, physical newspaper? Can you look at your fingertips and picture them smudged with ink, or remember trying to turn and fold those large and unwieldy pages? These are fading memories for me, and are probably totally foreign to many younger people today. Like many people, I consume virtually all of my news these days via the internet or, on rare occasion, the television. As far as I am concerned, newspapers are fast becoming nothing more than historical artifacts.
And yet, newspaper articles account for the bulk of the news data that I am analysing in my PhD project. To be sure, most of these newspaper articles were also published online, and would have been consumed that way by a lot of people. But I feel I can’t ignore the fact that these articles were also produced and consumed in a physical format. Unfortunately, there’s not much I can do to account for the physical presentation of the articles. My database doesn’t include the accompanying images or captions. Nor does it record how the articles were laid out on the page, or what other content surrounded them. But the metadata provided by Factiva does include one piece of information about each article’s physical manifestation: the page number of the newspaper in which it appeared.
From the very beginning of the explorations documented on this blog, I have completely ignored the page number field in my dataset. I figured that I was analysing text, not newspapers, and in any case I couldn’t see how I would incorporate page numbers into the kind of analysis that I was planning to do. But after hearing a colleague remark that ‘article-counting studies’ like mine are often unsatisfactory precisely because they fail to account for this information, I decided to give it some more thought. Continue reading Playing with page numbers