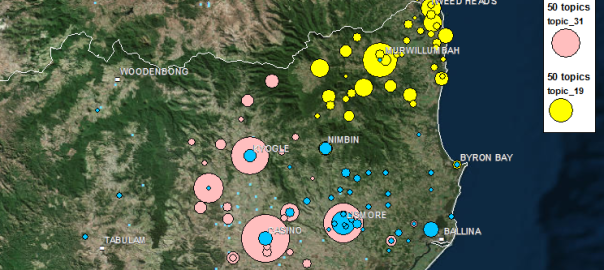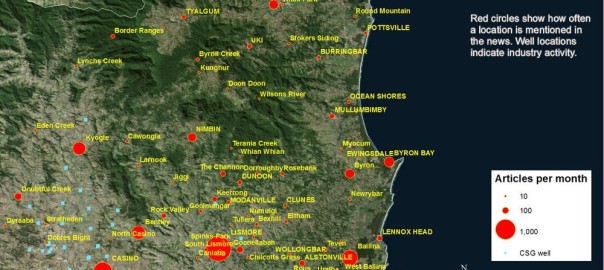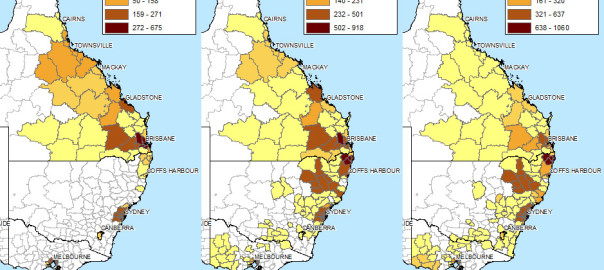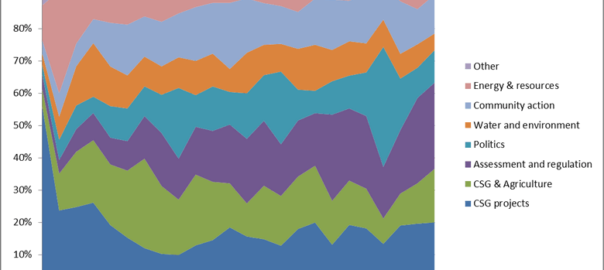
Months ago, I assembled a dataset containing around 40,000 Australian news articles discussing coal seam gas. My ultimate aim is to analyse these articles, along with other text data from the web, so as to learn something about the structure and dynamics of the public discourse about coal seam gas in Australia. I’m interested in dissecting how different parties talk about this topic, and how this ‘configuration’ of the public discourse changes over time.
Although I didn’t originally plan to, I’ve focussed much of my energy so far on exploring the geographic dimension of the news articles. I’ve looked at where the news has come from and what places it talks about. This is all important stuff to know when studying such a geographically defined issue as coal seam gas development. But I also need to know what is being talked about, not just where. Now, finally, I am ready to turn my attention to exploring the thematic content of the articles.
Well, almost. I’m ready, but the data isn’t. The dataset that I have been playing with all this time is stuffed with articles that I don’t want, and is missing many that I do. This is because the search parameters that I used to retrieve the articles from Factiva were very broad — I obtained every article that mentioned coal seam gas or CSG anywhere even just once — and because I applied a rather rudimentary method — keyword counts — for filtering out the less relevant articles. The dataset has served its purpose as a testing ground, but if I am to use it to actually say things about the world, I need to know what it contains. And more than that, I need the ability to customise what it contains to suit the specific questions that I decide to explore.
In other words, I need an index to my corpus. I need to know what every article is about, so I can include or exclude it at my discretion. In this post I’ll describe how I have created that index using a method of topic modelling called Latent Dirichlet Allocation, or LDA. Happily, this is the very same method that I was planning to use to analyse the thematic content of my corpus. So by creating an index for my corpus, I am already starting on the process of understanding what it’s all about. Continue reading What’s it all about? Indexing my corpus using LDA.