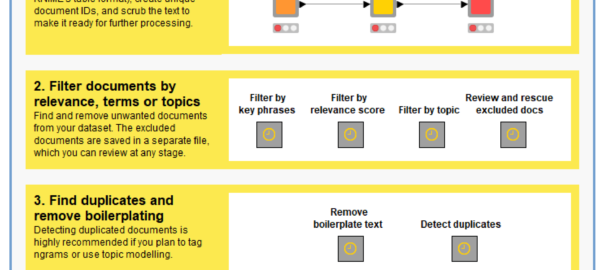
This post describes the motivation for the TextKleaner workflow and provides instructions on how to use it. You can obtain the TextKleaner workflow from the KNIME Hub.
Confronting the first law of text analytics
The computational analysis of text — or text analytics for short — is a field that has come into its own in recent years. While computational tools for analysing text have been around for decades — the first notable example being The General Inquirer, developed in the 1960s — the need for such tools has become greater as the amount of textual data that permeates everyday life has increased. Websites, social media and other digital communication technologies have created vast and ever-expanding repositories of text, recording all kinds of human interactions. Meanwhile, more and more texts from previous eras are finding their way into digital form. While all kinds of scholarly, commercial and creative rewards await those who can make sense of this wealth of data, its sheer volume means that it cannot be comprehended in the old fashioned way (otherwise known as reading). Just as computers are largely responsible for generating and transmitting this data, they are indispensable for managing and understanding it.
Thankfully, computers and the people who program them have both risen to the challenge of grappling with Big Text. As computers have become more and more powerful, the ways in which we use them have become more and more sophisticated. No longer a synonym for glorified word counting, computational text analysis now includes or intersects with fields such as natural language processing (NLP), machine learning and artificial intelligence. Simple formulas that compare word frequencies now work alongside complex algorithms that parse sentences, recognise names, detect sentiments, classify topics, and even compose original texts.
Such technologies are not the sole domain of tech giants and elite scientists, even if they do sit at the core of digital mega-infrastructures such as Google’s search engine or Amazon’s hivemind of personal assistants. Many of them are available as free or open-source software libraries, accessible to anyone with a well-specced laptop and a basic competence in computer science.
And yet, no matter how powerful and accessible these tools are, they have not altered a fact that, in my opinion, could be enshrined as the first law of text analytics — namely, that analysing text with computers is really hard. Continue reading TextKleaner – a Knime workflow for preparing large text datasets for analysis